

Can math help keep our streets safer?
A new study by a UCLA-led team of scholars and law enforcement officials suggests the answer is yes. A mathematical model they devised to guide where the Los Angeles Police Department should deploy officers, led to substantially lower crime rates during a recent 21-month period.
“Not only did the model predict twice as much crime as trained crime analysts predicted, but it also prevented twice as much crime,” said Jeffrey Brantingham, a UCLA professor of anthropology and senior author of the study. A paper about the work, which was also tested in Kent, England, was published online today by the Journal of the American Statistical Association.
UCLA reports that the model was so successful that the LAPD has adopted it for use in 14 of its 21 divisions, up from three in 2013.
Developed using six years of mathematical research and a decade of police crime data, the program predicts times and places that serious crimes will occur based on historical crime data in a given area. A key to its success, Brantingham said, is that the algorithm behind the model effectively “learns” over time.
“In much the same way that your video streaming service knows what movie you’re going to watch tomorrow, even if your tastes have changed, our algorithm is constantly evolving and adapting to new crime data,” he said.
Beginning in 2011, the researchers analyzed crime trends in the LAPD’s Southwest division and in two Kent divisions to determine whether their model could predict, in real time, when and where major crimes would occur. Their analysis in Los Angeles focused on burglaries, theft from cars and theft of cars. In Kent, they studied patterns for those crimes as well as violent crimes including assault and robbery.
The researchers tested the computer model by pitting it against professional crime analysts, seeing which could more accurately predict where crimes would occur. On each of 117 days in Los Angeles, they gave the human analysts a map of the entire police district and asked them to identify one precise location — only about half-a-block in size — where a crime would be most likely to occur within a specific 12-hour period. The algorithm was programmed to answer the same question (in this phase of the experiment, police officers did not act on the model’s predictions).
In Los Angeles, the mathematical model correctly predicted the locations of crimes on 4.7 percent of its forecasts, while the human analysts were correct just 2.1 percent of the time. In Kent’s two divisions, the model predicted 9.8 percent and 6.8 percent of the crimes; the analysts were correct 6.8 percent and 4 percent of the time. (Although those success rates might not appear to be dramatic, it’s important to note that the predictions were focused on minuscule target locations: The predicted hot spots represented less than 1 percent of Los Angeles’ land area, and an even smaller percentage of Kent.)
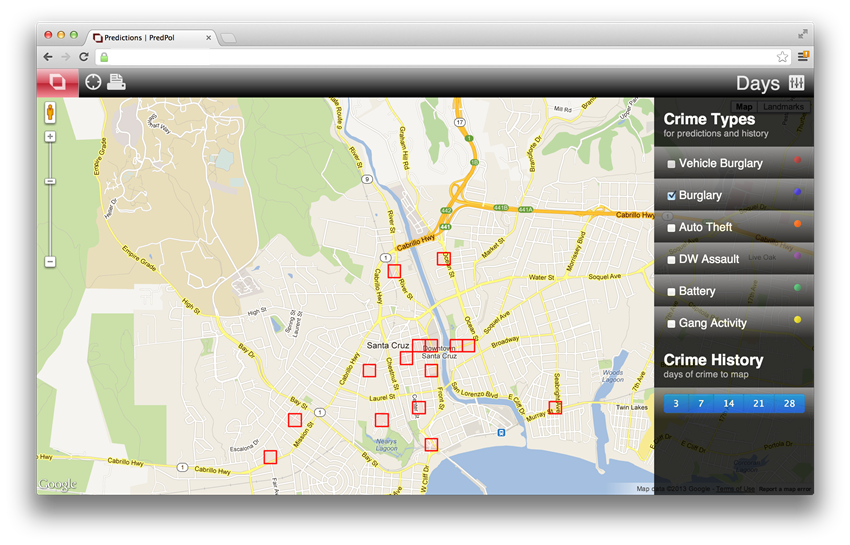
In the next phase of the study, police officers in each of three LAPD divisions — North Hollywood, Southwest and Foothill (in the northeastern San Fernando Valley) — were deployed to twenty half-block areas based on the predictions of either the model or the human analysts, on random days for between four and eight months. Neither the officers nor their commanders knew whether the assignments came from the computer or the professional analysts.
Officers were instructed to go to the specified areas, which were marked on maps as red boxes, to respond as they saw fit and to stay in the locations as long as they deemed necessary. Across the three divisions, the mathematical model produced 4.3 fewer crimes per week, a reduction of 7.4 percent, compared with the number of crimes that the police would have expected had officers not patrolled the “red box” areas. Crime was reduced when officers patrolled the areas selected by the human analysts as well, but only by two crimes per week in each division.
Based on those results, the researchers estimated that using the algorithm would save $9 million per year in Los Angeles, taking into account costs to victims, the courts and society. Brantingham said the mathematical model’s success rate could be improved even further as the researchers enhance the algorithm it uses. Based on its own test run, the Kent police now are rolling out the mathematical model to other divisions throughout the county.
“We have worked closely with counterparts in Los Angeles from the moment we became interested in predictive policing and the benefits it brings to keeping communities safe,” said Mark Johnson, head of analysis for the Kent police.
Brantingham thinks the mathematical model would be effective in cities worldwide. UCLA notes that he is a co-founder of PredPol, a company that markets predictive policing software to cities including Atlanta and Tacoma, Washington. Brantingham also emphasized that the algorithm cannot replace police work; it’s intended to help police officers do their jobs better.
“Our directive to officers was to ‘get in the box’ and use their training and experience to police what they see,” said Cmdr. Sean Malinowski, the LAPD’s chief of staff. “Flexibility in how to use predictions proved to be popular and has become a key part of how the LAPD deploys predictive policing today.”
Many social scientists have said human behavior and criminal behavior are too complex to be explained with a mathematical model, but Brantingham strongly disagrees.
“It’s not too complex,” he said. “We’re not trying to explain everything, but there are many aspects of human behavior that we can understand mathematically.”
— Read more in G. O. Mohler et al., “Randomized controlled field trials of predictive policing,” Journal of the American Statistical Association (7 October 2015) (DOI: 10.1080/01621459.2015.1077710)